Guide Labs
— Interpretability Researcher, San Francisco
Guide Labs
— Interpretability Researcher, San Francisco
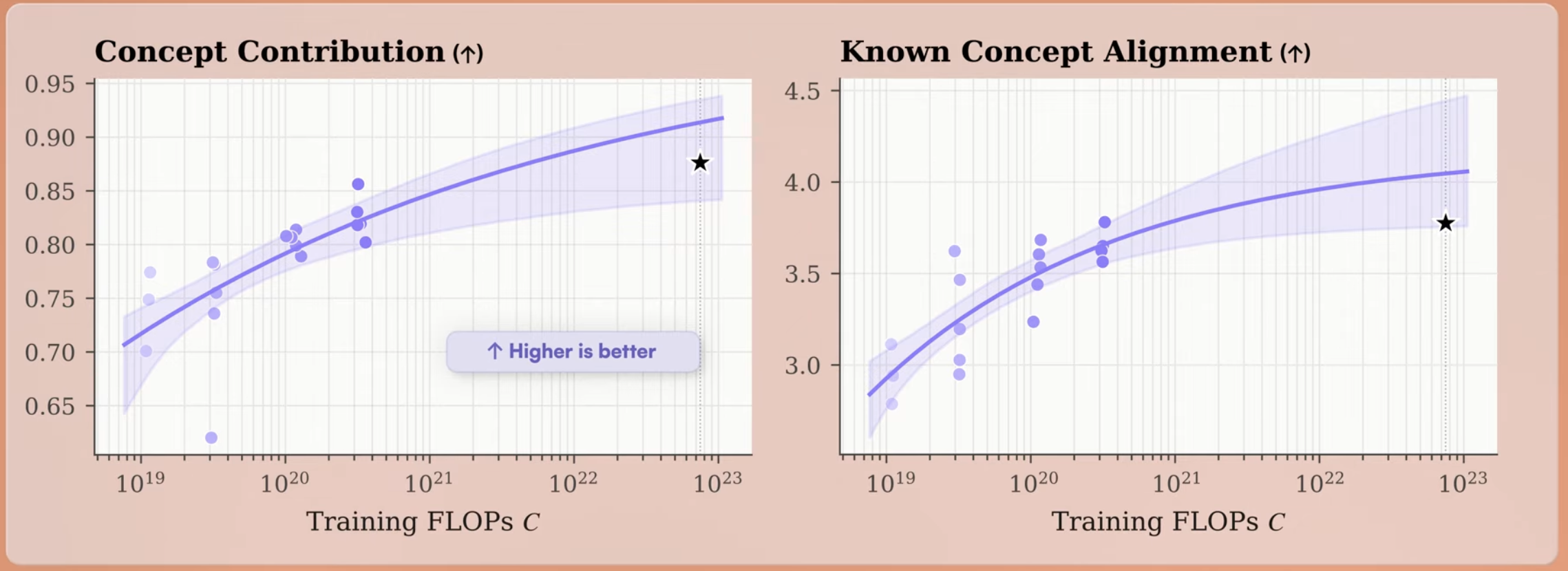
- Train: First large-scale inherently interpretable language model, Steerling-8B, pretrained on trillions of tokens.
- Explain: Attributing model behavior at the concept, prompt, and input-to-concept levels.
- Control: Controllable generation for topic steering and safety alignment without fine-tuning.